KPI Genealogy
There was a project I worked on a long time ago where I was brought in to provide some data science magic on why this group’s KPI wasn’t moving. A KPI is a Key Performance Indicator: something you use to tell you the heartbeat of your business. Are the things we doing having a good or bad impact over time? You’d answer that question with a KPI like how many people are satisfied with your product over time.
This group was using a KPI called NSAT: short for Net Satisfaction. It’s a commonly used KPI in various marketing industries and is derived from a Net Promoter Score. A Net Promoter Score is when you give someone a survey with a bunch of different options and take the difference between whatever you define as the “top box” and the “bottom box”.
|
Bottom Box |
Top box | |||
|
Strongly-Disagree |
Disagree | Undecided | Agree |
Strongly-Agree |
| 1 | 2 | 3 | 4 |
5 |
Above is an example of a 5 point survey. A top box in this case might be our score of 5 or “Strongly Agree” and our bottom box might be the score of 1, or “Strongly Disagree”. This was developed by a marketing guru decades ago named Freidrick Reichheld [1]. What Reichheld did specifically was to blur the lines further into promoters and detractors like so:

There’s many ways to calculate a net promoter score. One case might be summing up the number of 10’s and 9’s, then subtracting the 0’s through 6’s. That might give us a number which we can use to compare to other net promoter scores.
Reichheld talks at length how calculating a Net Promoter Score is used as a metric to determine customer loyalty. Some corporate entities have a bad habit of simply using a KPI because other people do without asking why they use it. There’s many criticisms about Net Promoter Score which I won’t delve into here [2], but the takeaway message is that it’s a simple number you can use to gauge how likely your customers are to recommend something.
Blast from the Math
The org I was working with was calculating their Net Promoter Score like so:
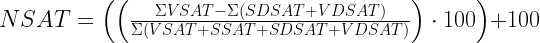
Basically: a number between 0-200 that we get as a result of the number of Very Satisfied (VSAT) respondents subtracted by the sum of Somewhat Dissatisfied (SDSAT) and Very Dissatisfied respondents (VDSAT), that whole thing divided by the total number of respondents.
In this case we only have 4 buckets in our survey: VSAT, SSAT, SDSAT, and VDSAT. One thing I noticed right away when dealing with this metric: where’s the Somewhat Satisfied respondents? I didn’t like the idea of throwing out one of the bins entirely so I asked around. The response I got from colleagues was that they were only interested in people who really cared about the system we were using.
Another issue was the calculation itself was negatively biased. Let’s say we have equal numbers of VSAT, SSAT, SDSAT, and VDSAT respondents. One would expect our score to be 100, a nice happy halfway point between 0 and 200. However, the real NSAT halfway point on a uniform distribution is 75. This is because we don’t use SSAT in the calculation’s numerator.
For clarification, this org was in the web support space. I don’t know if you’ve ever had issues with your computer and wanted a solution only to be bombarded with an online survey before you could fix it. If you have, I’m almost positive you weren’t having a great time to begin with. These kinds of initial biases of the user can have a huge impact on survey data. Someone comes to your site in a bad mood and you ask them how they’re doing, then wonder why your calculated metric isn’t working as intended. Oops.
The way the math of the formula is written to calculate NSAT, it’s very sensitive to Very Satisfied survey counts. If those were to drop by a small amount, despite the overall VSAT+SSAT pool remaining the same, it has a huge impact on the calculation of the number.
Sso Wheress the SSAT?
Part of the problem with this formulation is that simply adding the SSAT bin back into the calculation doesn’t really solve our problems.

Above, we’ve added the Somewhat Satisfied respondents back in to the equation. Why is this a problem? Let’s take a look at some distributions of data:

The issue with adding SSAT back in, is that we have a problem of giving too good a picture of what our satisfaction metric should be like. While we get a number of 100 for a uniform distribution (final row) with NSAT2, if we have 50% of our data being in SSAT and the other 50% in VSAT, we get a perfect score of 200. Probably not the best approach, but we’re getting closer.
Another issue we see from the above table is information loss. In the top two rows where we have 100% of our respondents who are very dissatisfied, the second row shows them moving to somewhat dissatisfied. This should be a quantifiable measurement, but NSAT fails to see this movement. Likewise does NSAT2.
Quantitative Satisfaction: QSAT
Instead of just slapping SSAT back in, we need a smarter approach. There’s two variables we have to pin down first, one being the score range that we’re interested in, and the other the number of survey bins.
- Let’s define B bins, where a bin is a user satisfaction response like “very dissatisfied”, “neutral”, or “very satisfied”, etc.
- Let’s also define a score range R as a maximum score in a given range (ie 0-200).
- We also need to define some offset, Z, as an initial starting number of bins in which we set the score explicitly to zero. For example, NSAT uses the “very dissatisfied” response as its first bin and all those surveys are scored as zero.
So our score per bin is:
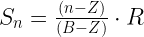
So our end result would be a weighted average of the formulated score over the given range of the bins:

or more compactly:

If we wanted to simply rewrite our old NSAT formula that has range R=200, and one bin that’s set to zero, Z=1, and utilize the same four bins as before, we could rewrite NSAT in this new QSAT form as:

America’s Next Top Quantitative Satisfaction Model
Given the concern with NSAT’s information loss and NSAT2’s inherent positivity bias in addition the underlying problems of its NSAT-based model foundation, we can are motivated to check how QSAT performs in comparison:

We’ve solved both the information loss and over-biased issues with NSAT2 now. When we move our respondents from the VDSAT to SDSAT bins, we can record that change. If we have 50% of our data split between the top two buckets, the KPI isn’t maxed out. Another important feature is the uniform distribution in the final row: we’ve hit the expected 100 mark that makes logical sense.
Case Study: Support Site
Between the months of January and April 2014, some org logged a large number of survey-based responses. In total, 138,724 surveys were recorded in that time and a distribution can be seen as follows:

You’ll notice right away that the peak of the distribution is on the positive end with 46% of the total responses being Somewhat Satisfied. 64% of the surveys are positive overall, but the way NSAT negatively biases the data giving us a score of 87.16, you would assume that something bad was happening given the 0-200 scale.
If instead we use the QSAT to measure the survey responses, we get a much different picture:

A score of 114 versus 87 is a big difference. Losing out on 27% of your KPI because of a poor formulation is a bad idea. Ditch the tradition and let the math guide you to something more reasonable. If you can’t defend why you’re using your KPI, you shouldn’t be using it.
References
[1] Reichheld, Frederick F. “The one number you need to grow.” Harvard business review 81.12 (2003): 46-55.
[2] Grisaffe, Douglas B. “Questions about the ultimate question: conceptual considerations in evaluating Reichheld’s net promoter score (NPS).” Journal of Consumer Satisfaction Dissatisfaction and Complaining Behavior 20 (2007): 36.
header image from estetikaparis.com
