Every so often I’m at a loss to suggest what game I should recommend me and all my friends get together and play. Sometimes I’m at a loss for what game even I should be playing. After ruminating and playing around with some modelling scenarios, I think I may have designed a pretty decent game recommendation system for Steam.
This more or less started when we were trying to rate which games we’ve played in the past (on PC) out of 10, then trying to find games similar to those to play next.

Some of us didn’t rate many games, others did but had wild disagreements about how good it was or not. This self-rating system wasn’t great because of how subjective the ratings were. How can we compare a Will 8.5 to a Scott 8.5, for example? Each person has different tastes and genres they may like and trying to map those to others is a recipe for disaster.
In this post, I’m examining how to build a recommendation system based on Content Filtering. This is where we build a user profile of data based on genres, then apply that to a game’s genres to figure out a score and rank them accordingly.
If you’re not interested in code, feel free to jump all the way down to the “Results” section at the bottom.
Time To Play
One way I thought to reformulate this question was to look at a different metric instead of a personal rating. I figured someone likes a game a lot if they spend a lot of time with it. Either that, or it shows a lot of user engagement anyway. We can use someone’s total in-game play time instead to get a measurement for how engaged with a game they might be, instead. That way we have a number which we can compare across individuals in a more objective light.

According to my own games’ listed play times, I’ve been the most engaged with Planetside 2 by a wide margin. Yet, there’s other games that I’ve thought very highly of but don’t spend a lot of time with at all. If I were to sit down and play some Super Hexagon, or Devil Daggers, I might play either for only a couple minutes at a time before putting it down and playing something else. It’s important, therefore, to look at how an individual’s playtime compares with that of the population.
In order to compare how my play times compare to the rest of the world’s I went to SteamSpy and dug up the numbers on all my games. Let’s take a look at Dark Souls 3, for example. I’ve played about 65 hours of the game, but the median total playtime for it is at 50.41 hours (when I recorded that data anyway). So I’ve put in about 15 hours over the median user of the game. That’s not bad, but could we map that to a more binary yes/no level of recommendation?
We can do this is a couple different ways. The more statistical approach would be to simply measure what percentile of the distribution of gamers I fall in in terms of playtime. Calculating this is rather expensive, though, and while SteamSpy has that data on hand to some extent, mining it is pretty difficult, since we need the distribution of total playtime data for each game.
A far faster approach that we can apply to all games in our dataset is to just look at the difference in our playtime hours compared to the median. That will give us some number, but then we can use a sigmoid function to more or less normalize that across the different games.
Enter the Sigmoid
The sigmoid is a named function that has a form like:
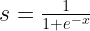
and has a plot that looks like:

So it’s output ranges from 0 to 1 based on what numbers we put in it. The number that we could put in could be

What we’re doing here is seeing how big the difference is between someone’s total playtime with a game, and the overall population’s median user. The reason why I choose median here instead of average is that lots of games on Steam have very skewed distributions and using the average playtime might be more bent towards the end of enthusiast gamers in niche games.
The reason why I use hours here instead of the Steam API’s default of minutes is that the sigmoid function is very sensitive to the number we put in. So if we put in a game where the median play time is 20 minutes, and we have 30 minutes of total play time, then the sigmoid will be activating on the number 10, which suggests a strong level of engagement. However, if we look at the difference in hours and the sigmoid is activating on 0.167 instead, then the result is much closer to 0.5: a middle-of-the-road level of engagement.
So how does this apply to my games’ total playtime? Let’s take a look:

Planetside 2 hasn’t been dethroned, but the rest of the landscape has changed quite dramatically. Geometry Wars 3 is right up there in 2nd place, with Dark Souls up to third from its sixth position previously. Many of these games are smaller, indie titles like Spelunky, Fez, and VVVVVV which have a much smaller level of user engagement in the population. This begs the question of what the distributions look like for certain games versus others. Do lots of people buy Fez, play for 5 minutes, then stop ever playing it, thereby bringing the median way down?
Motivating Prediction
We have the basic underpinnings of a model that we can use to recommend games to ourselves and friends. What we want to predict is how likely someone is to be engaged with a certain game. We’re not predicting whether or not the game is good per se, but whether the user will spend enough time with it compared to the rest of the population to make it worth their while.
Because the sigmoid is dependent on the user’s playtime, we basically have to predict that first. So how do we go about predicting if a user is likely to spend time with a game in the first place?
One great thing about steam spy (and I’m not sure why the steam store api doesn’t have this) is that we get a distribution of app tag data.

So for Geometry Wars, we have a bunch of categories and numeric values tied to them. Action: 46, Arcade: 41, Twin Stick Shooter: 36, etc. This is great because we can use this as the basis for a profile.
There’s many ways to recommend a product to someone using algorithmically-driven scenarios. My initial approach here was to build out a table of data that would gave a game, my total playtime, then joining on another table of the tag data, then running some kind of supervised machine learning algorithm on top of it to predict my total playtime for games I haven’t played yet, but that I have the tag info for.
The issue with this, as we shall see, is that each game only has about 10 tags to it (some fewer). There are something like 120ish or so unique tags on steam, so each row of data is going to have lots of zeroes in it. The solution here is to keep it simple and just use a dot product between a profile of preferences and the tag data we have.
So let’s say I do some manipulation of the data and come to build out a profile for myself that looks like this:

Here I have some genres (or tags) and what my rating (or sigmoid-applied playtime over median) are. Let’s say we have a bunch of games that we want to predict our ratings for. We have their tags as well on a binary scale of 0-1:

All we do here is take the inner (or dot) product between the row of game data and the column of genre ratings. So for game A, our score would be :

giving us a result of 12.31.

Here I’ve added the individual game ratings. We see that game D is the one with the highest rating, so we should play that one first.
Data Collection
Data collection for this is a three-pronged approach:
- We need game playtime for an individual user
- We need a game’s median playtime
- We need a game’s distribution of tag data
Stage 1: Getting User Playtime
So normally, steam has a nice API to pull all this info from so you don’t have to reference a flat file, but for whatever reason when I was playing with this at the time I needed to just save my own data pull then load it into a data frame.
Anyway, to get your own app usage info, use the steam api and some kind of key like this:
That will get you a .json file which has all the info you need.
Stage 2 & 3: Getting Median Playtime and Tag Counts
Welcome to code land! In this section I’m going to hammer through some R code that will build us out a data set for prediction. *Editor’s caveat: this was designed a while ago where my go-to method was to just scrape SteamSpy and store the data locally.
This code is done in a number of steps:
- Loading up all the steam user data (games, playtime)
- Scraping SteamSpy per game to get median playtime and tag count info
- Appending SteamSpy info into a single table
- Pivoting the SteamSpy info to be a wide-form table
- Joining the SteamSpy info onto our user data
Part 1: steam user data
library(jsonlite)
library(XML)
library(lubridate)
library(RCurl)
library(tidyr)
library(plyr)
scalar1 <- function(x) {x / sqrt(sum(x^2))}
sigmoid1 <- function(x) {1 / (1+exp(-x))}
gamedata <- fromJSON("my_data.json")
gamedata_df <- data.frame(gamedata)
gamedata_keep <- subset(gamedata_df, select=c("response.games.appid", "response.games.name", "response.games.playtime_forever"))
gamedata_keep$response.game.playtime_hours <- round(gamedata_keep$response.games.playtime_forever / 60)
#use steam app id list to get steam tags per app id
alltags <- data.frame(matrix(0,1,5))
names(alltags) <- names(tags4)
median.playtime <- data.frame(matrix(0,1,2))
names(median.playtime) <- c("response.games.appid", "median.playtime")
Most of the code chunk above is just pre-allocating for building out our dataset. We're loading libraries, setting up functions for calculating some stuff later, loading in our steam user data from a JSON file, selecting some relevant info from that, then setting the stage for our table of SteamSpy data.
Part 2 & 3: scraping SteamSpy
for(i in gamedata_keep$response.games.appid){
url <- sprintf("http://steamspy.com/app/%i", i)
html <- getURL(url, followlocation = TRUE)
# parse html
doc = htmlParse(html, asText=TRUE)
plain.text <- xpathSApply(doc, "//p", xmlValue)
text.parse <- plain.text[2]
tags.parse <- sub(".*?Tags: (.*?)Category.*", "\\1", text.parse)
playtime.parse <- sub(".*?Playtime total: (.*?)median.*", "\\1", text.parse)
#match playtime to app id in gamedata_keep
playtime.parse2 <- data.frame(strsplit(playtime.parse, " "))
playtime.parse3 <- data.frame(i, playtime.parse2[3,1])
names(playtime.parse3) <- c("response.games.appid", "median.playtime")
median.playtime <- rbind(median.playtime, playtime.parse3)
#reshape app id tags. use raw number counts, % of total, and new noramlization formula
tags <- strsplit(tags.parse, ",")
tagsdf <- data.frame(tags)
names(tagsdf) <- c("tags")
tags3 <- separate(data = tagsdf, col = tags, into = c("tag", "num"), sep = "\\(")
tags4 <- separate(data = tags3, col = num, into = c("num", "del"), sep = "\\)")
tags4$del <- NULL
tags4$num <- as.numeric(tags4$num)
tags4$percent <- prop.table(tags4$num)
tags4$norm <- scalar1(tags4$num)
tags4$appid <- i
alltags <- rbind(alltags, tags4)
}
As you can probably tell from the comments, we first take the appid from our user play list, find the corresponding SteamSpy site, parse the HTML on the page to get the median play time and the tag data, then slap all that together and bind it to our pre-allocated data frame from before. We then repeat this over the entire list of game IDs that a user has played.
Part 4: pivoting the tag data
tag_p <- data.frame(alltags$appid, alltags$tag, alltags$percent) library(reshape2) tag_d <- dcast(tag_p, alltags.appid ~ alltags.tag, fun.aggregate = mean) tag_d[is.na(tag_d)] <- 0 tag_matrix <- data.matrix(tag_d) tag_heat <- heatmap(tag_matrix, Rowv=NA, Colv=NA, col=heat.colors(256), scale="column", margins=c(5,10))
In this step, we're taking the tag data to be from long form and re-casting it to be in wide form. This pivot or cross-tabulation is a common data manipulation tactic in SQL or Excel, and it's just as easy in R. Sean Anderson has a great writeup on how it works in R if you want a more in-depth tutorial on that front.
Let’s take a code break and look at the tag data transformation. I’ve stuck with using the percent of tag data instead of the raw numbers for prediction purposes later. The percents are just the raw numbers divided by the total number of tag count for a given game so they’re all in the same range.
We start with a table of tag data that looks like:

and transformed it to look like:

You might be asking yourself “well that seems like a useless step. Look at all the zeroes in that table! How is any of that useful?” You’d be right to be amazed at how sparse the data is. A more compact way of showing that is with a heatmap where each cell of the table is colored according to its value. Red, in this case, is zero, and yellow is closer to 1:

What we’ll notice is that there’s a lot of 0 data in the table. It makes sense because we’re taking some games that are pure shooters and might have tags associated with those, and putting them on the same playing field as maybe puzzle games, which have a totally different distribution of tags. The end result is that all tags for all games are listed across the columns and all the games a user has played in the rows.
One might be tempted to slap some kind of machine learning algorithm on top of this data without really understanding the consequences. The issue is that with so many 0’s in the data, we can’t really do much with a supervised learning algorithm. However, if we do something simple like a dot product of this table of data with a user profile, we can get a much better result since all the 0’s are basically ‘tossed out’ of the analysis.
Part 5: bringing it all together
What we need to do first is to build a profile for our user to understand which genres of games they like best. In my case, we have my sigmoid number per game and we can join on the big sparse tag data frame to those games. What we then want to do is to distribute that sigmoid score through the various tags per game to get a kind of “sigmoid per game” score. We then want to aggregate those through all the tags in order to sort by which tags I like the best. The R code below handles just that:
library(dplyr)
gamejoin_full <- left_join(gamejoin_keep, tag_d, by=c("response.games.appid" = "alltags.appid"))
gamejoin_complete <- gamejoin_full[complete.cases(gamejoin_full),]
gamejoin_sigmoid_ratings <- gamejoin_complete[["sigmoid"]] * gamejoin_complete[-(1:5)]
tag_sums <- colSums(gamejoin_sigmoid_ratings)
tag_sums_df <- data.frame(names(gamejoin_complete[-(1:5)]), tag_sums)
The end result looking like this:

So clearly I like action, adventure, and FPS games the most. Any game that has these types of tags will rate highly. The real question is the degree to which they have those tags. Remember: we have tag data as proportional percentages per game. So a game that is 99% co-op and 1% action will likely rate lower than a game that is 99% action and 1% co-op, given the way a dot product with vectors works.
Ok so that’s part one. The next part is to apply our profile data to some new stuff. I got the steam IDs from all the games on my wishlist, then parsed them through my SteamSpy scraper from above and repeated the pivot process to get that same sparse tag data table we saw before, but only for games that I’m interested in and haven’t played yet. R code below:
wishlist_ids <- c("387290", "332200", "367520", "404540", "590380", "460810", "294100", "361420", "400450", "242680", "619680", "509350", "2910", "243970", "277390", "396750", "382560", "239090", "242860", "358040", "536890", "211820", "322170", "291860", "249050", "440550", "306130", "368340", "628900")
library(tidyr)
alltags2 <- data.frame(matrix(0,1,4))
names(alltags2) <- c("tag", "num", "percent", "appid")
for(i in wishlist_ids){
#i<- c("387290")
url <- sprintf("http://steamspy.com/app/%s", i)
html <- getURL(url, followlocation = TRUE)
doc = htmlParse(html, asText=TRUE)
plain.text <- xpathSApply(doc, "//p", xmlValue)
text.parse <- plain.text[2]
tags.parse <- sub(".*?Tags: (.*?)Category.*", "\\1", text.parse)
tags <- strsplit(tags.parse, ",")
tagsdf <- data.frame(tags)
names(tagsdf) <- c("tags")
tags3 <- separate(data = tagsdf, col = tags, into = c("tag", "num"), sep = "\\(")
tags4 <- separate(data = tags3, col = num, into = c("num", "del"), sep = "\\)")
tags4$del <- NULL
tags4$num <- as.numeric(tags4$num)
tags4$percent <- prop.table(tags4$num)
tags4$appid <- i
alltags2 <- rbind(alltags2, tags4)
}
#little bit of data cleanup needed here...
write.table(alltags2, "F:\\docs\\dev\\R\\alltags2.txt", row.names=F, quote=F, sep="\t")
alltags2 <- read.table("F:\\docs\\dev\\R\\alltags2.txt", header=T, sep="\t", quote="")
library(reshape2)
alltags2_p <- select(alltags2, -(num))
One important aspect of data cleanup, however, is to make sure the tags in this wishlist table match up to the tags that we have for my profile data. In my wishlist tags table above, I have 115 tags. In my tag profile data I have 242. Some of these line up, some don't. In order for the dot product to work correctly we need alignment between these two so we don't have a tag like "6DOF" getting applied to the profile data which has no corresponding tag.
I'm doing this in a roundabout kind of way, but the philosophy of the dot product is still there 🙂 . In the code chunk below, I'm subsetting the "alltags2_p" data frame for the relevant game, joining that onto my profile data then applying the dot product as a simple columnar multiplication and summing it up. Then I'm appending that data to a final data frame which we'll sort at the end of the day:
wishlist_scores <- data.frame(matrix(0,1,2))
names(wishlist_scores) <- c("game", "score")
for(i in unique(alltags2_p$appid)){
#i=460810
testsub <- subset(alltags2_p, appid==i)
testjoin <- left_join(tag_sums_df, testsub, by=c("names.gamejoin_complete…1.5…"="tag") )
testjoin[is.na(testjoin)] <- 0
testjoin$score <- testjoin$tag_sums * testjoin$percent
tempdf <- data.frame(i, sum(testjoin$score))
names(tempdf) <- c("game", "score")
wishlist_scores <- rbind(wishlist_scores, tempdf)
}
Results
And finally our end result (with a little bit of added analysis):

We’re left with games and scores based on how they line up with my favorite genres. I’ve listed the original rank they were in my wishlist by position, with 1 being the top game I was interested in at the time.
The list has jumbled around quite a bit! I was shocked to see RunGunJumpGun up at the top of the list and RimWorld shot down towards the bottom. Seeing Videoball and Samurai Gunn up so high also came as a surprise. I had been interested in those games for some time, but wasn’t super bowled over by them to actually buy just yet. I think mostly because they seem like better split screen couch games than playing online. In any case, seeing Terra Mystica up so high shouldn’t come as much of a surprise, since I’ve been on a streak of playing boardgame apps that have been released on Steam lately.
Summary and Final Thoughts
We’ve gone over a lot of code and a lot of steps, so I figured I’d hit the major bullet points in case you’re looking for a TL;DR:
- Use Steam API to get your list of games and your playtime
- Scrape SteamSpy to get the median playtime for a game and a game’s distribution of tag data
- Define your engagement with a game by taking the difference between your playtime and the median for a game. Pass that through a sigmoid function to more or less normalize the scores
- Join the tag data for games you’ve played to your sigmoid score, then multiply that score through the tag data and sum up per tag. This develops a profile for which tags you like the best based on your sigmoid score
- With that handy profile data, compute a dot product with a game you’re interested in’s tag distribution. This gives you that game’s final score
- Sort by score!
Some aspects I’d look into further: using my individual percentile per game instead of a sigmoid. This might be more accurate than simply doing sigmoid(my_time – median), but the latter is certainly faster than manually scraping that data from SteamSpy.
I think a fun next step to this analysis would be to have the final loop run over *all* app ids in steam. I’m sure there’s some games out there that I have no clue about which might match my distribution of tag preferences to great effect.
In my case I applied this prediction to games in my Steam wishlist since there was a lot of data in there already. However, having this kind of data setup only really works for users that have played a good number of games to build out a reasonable portfolio of tag preferences. If you have a user who just plays 2 games and you have 10 or 20 tags to work with, you might not be able to predict so well. The way around that, I think, is the Steam discovery queue. So if I were putting this into production on Steam’s backend, I’d probably build a user profile based on their discovery data if a user has something like less than 10 games played. I imagine it would be a good way to seed the data first before starting predictions.
